AI Technical Writer

Introduction: The Uniform Model Tax
Here is a request that just hit your production API:
"Are there any syntax issues here?
prices_usd = {'laptop': 1200, 'mouse': 25, 'monitor': 300}
expensive_items_eur = {k: v * exchange_rate for k, v in prices_usd.items() if v > 50}
print(expensive_items_eur)"
A syntax check.
The answer is no, there are no issues.
Any model from a $0.10/million-token tier can answer this correctly in under a second.
Now here is the next request from the same agent session, three seconds later:
"We're migrating our monolith to microservices. The current architecture uses a
shared PostgreSQL instance with 47 tables. Identify which tables are safe to split
into separate service databases without introducing distributed transaction risk,
and propose a phased decomposition strategy."
This is a different query entirely. It requires architectural reasoning, understanding of distributed systems tradeoffs, and the ability to synthesize a multi-step migration plan. This is a complex task for a frontier model.
Most production systems today treat these two requests as the same. They route both to the same model; typically, the most capable one, because building anything smarter requires infrastructure that most teams don’t have time to build. In this case, you pay frontier rates for every request, including the overwhelming majority that don’t need frontier capability.
The numbers compound quickly. In a typical coding agent session, the distribution of task complexity looks roughly like this: In a typical coding agent session, the majority of requests are simpler tasks — syntax checks, short lookups, basic explanations — while a smaller share requires the kind of multi-step reasoning only frontier models handle well. If you’re routing everything to a model priced at $15/million output tokens, you’re paying that rate for work that a $0.30/million-token model handles just as well.
Key Takeaways
- Sending every request to one model is expensive. Most requests in a production workload are simple — syntax checks, short lookups, basic explanations. Paying frontier model rates for all of them adds up fast.
- The Inference Router picks the right model per request automatically. It reads each request, matches it to a task type you’ve defined, and sends it to the most cost-effective model available for that task.
- Routing accuracy is 87.84% on the 30B-A3B model — higher than GPT-5.1 (86.93%) and Claude Sonnet 4.5 (86.11%) on the same benchmark.
- For agentic loops, use session pinning. The
X-Model-Affinityheader locks a session to one model, which preserves the cached context and reduces input token costs by 45–80% per turn. - Getting started is a one-line change. Replace
"model": "gpt-5.2"with"model": "router:software-engineering"in your existing API call. Everything else stays the same.
Why Teams Don’t Route Today
Option 1: Hardcoded routing logic in application code. You write conditional branches, such as if the prompt contains “explain” or “summarize,” use the cheap model; otherwise, use the expensive one. This breaks immediately. “Explain why this race condition occurs and fix it” gets routed to the cheap model. “Write hello world” with a sarcastic tone accidentally triggers the expensive path. Keyword-based methods cannot understand context or meaning. Every model or task change requires a code deployment. You’ve turned model selection into a feature you own and maintain indefinitely.
Option 2: A classifier LLM as a routing layer. Use a small model like Claude Haiku or GPT-4o-mini to classify intent, then dispatch to the right model. This is conceptually sound but introduces a new problem: you’re paying for two inference calls per user request; one to classify, one to respond. Worse, a general-purpose model prompted to classify isn’t optimized for that task. Accuracy suffers in edge cases. And you’ve doubled your latency on the critical path before the user sees a single output token.
Neither option scales. Both put routing logic where it doesn’t belong: in application code or in a general-purpose model that wasn’t built for the job.
What Routing Actually Requires
To route requests correctly at scale, you need three things:
1. Semantic intent resolution. Not keyword matching and actual understanding of what a conversation is asking for, accounting for multi-turn context. A message that says “do the same for New York” means nothing without the preceding turns. A message that says “fix it” in a coding session means “fix the bug we were just discussing,” not “fix the syntax.” Any routing system that can’t reason over conversation context will fail on real agentic traffic.
2. Live performance signals. Model cost and latency are not constants. Provider pricing changes. Latency fluctuates by 2–3× throughout the day based on traffic load — the fastest model at 2 am is often the slowest at 2 pm. A routing system built on static configuration bakes in assumptions that will be wrong within weeks.
3. Infrastructure-level execution. Routing that lives in application code is routing that the application team has to maintain. When models are added, deprecated, or repriced, the routing logic needs updating. When an agent framework changes, the routing wrapper breaks. Routing belongs at the infrastructure layer — below the application, invisible to it, and updatable without touching application code.
This is where inference-time model routing as an infrastructure primitive becomes important.
The Research Foundation
Using different LLMs to balance cost and quality is supported by strong research.
FrugalGPT (Chen et al., 2023) was among the first papers to bring out this novel approach: By sending requests to models from least to most powerful and stopping when a model is confident enough, you can achieve GPT-4-level quality at up to 98% lower cost on standard benchmarks. The core insight was that most queries don’t need the most expensive model; the hard part is knowing which ones do.
RouteLLM (Ong et al., 2024) extended this by learning routing policies from human preference data rather than constructing them by hand. Their best router achieved a 2× cost reduction while preserving 95% of GPT-4 quality on the Chatbot Arena benchmark. The key finding: a small classifier trained specifically for routing substantially outperforms prompting a general-purpose model to make routing decisions. Purpose-built beats general-purpose for narrow, well-defined tasks.
More recently, LLMRouterBench (2026) introduced a unified evaluation framework across routing methods, confirming that learned, task-specific routers consistently dominate rule-based and prompted approaches across quality, cost, and latency dimensions.
The academic case for intelligent routing is clear. The missing piece was production infrastructure that makes it a one-line change rather than a multi-week engineering project.
The DigitalOcean Approach
DigitalOcean’s Inference Router is built on a different premise than the options above. Rather than a general-purpose classifier or a set of application-layer rules, it uses a purpose-built Mixture-of-Experts (MoE) model fine-tuned specifically for routing across multi-turn conversations. It uses a purpose-built routing model called Plano-Orchestrator, developed by Katanemo (now part of DigitalOcean) and available in a 4B dense variant and a 30B-A3B MoE variant that activates only ~3B parameters per routing decision. It runs inside Plano, the open-source AI-native proxy that powers the Inference Router’s infrastructure layer.
Using it looks like this:
from openai import OpenAI
import os
client = OpenAI(
base_url="https://inference.do-ai.run/v1",
api_key=os.environ["MODEL_ACCESS_KEY"]
)
# Before: every request hits gpt-5.2 regardless of complexity
response = client.chat.completions.create(
model="openai-gpt-5.2",
messages=[{"role": "user", "content": prompt}]
)
# After: the MoE router dispatches each request to the right model
response = client.chat.completions.create(
model="router:software-engineering",
messages=[{"role": "user", "content": prompt}]
)
# Which model actually handled this request?
print(response.model) # e.g., "openai-gpt-oss-120b" or "anthropic-claude-sonnet-4.5"
The model field in the response tells you exactly which model handled the request. The routing decision is fully observable. The application code is identical except for one string.
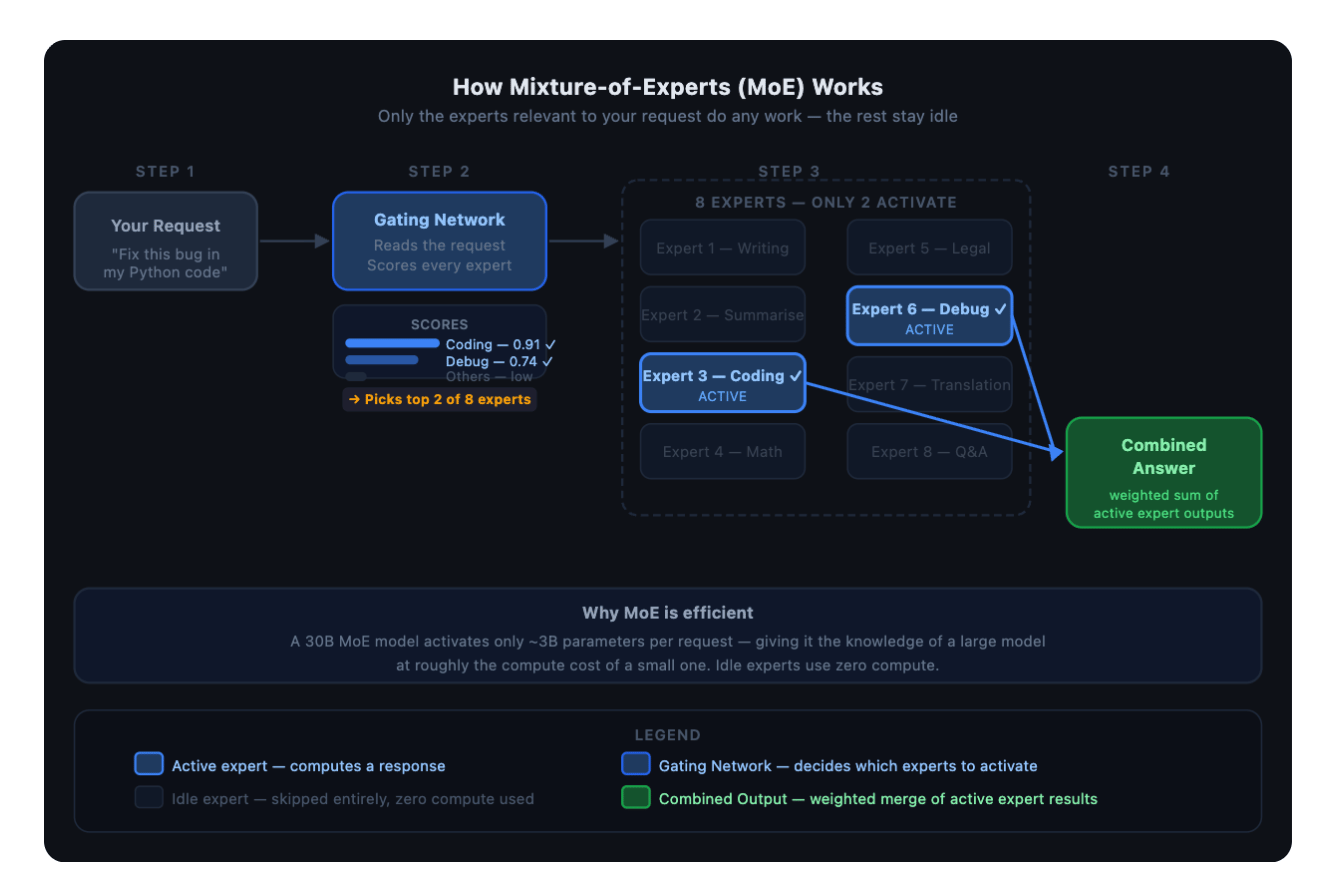
Why is MoE known as the Routing Brain?
Two concepts come together in this article: routing and Mixture-of-Experts (MoE). It’s worth defining both clearly before getting into how both of this combines.
Routing means automatically deciding which model handles a given request, instead of sending everything to one hardcoded model. A router sits in front of your model pool, reads each incoming prompt, figures out what kind of task it is, and dispatches it to the model best suited for that task. A simple syntax check goes to a cheap, fast model. A complex architecture question goes to a frontier model. The application code doesn’t change, and only the string in the model field.
Mixture-of-Experts (MoE) is a model architecture where, instead of running all parameters for every input, the model has a set of specialized sub-networks (experts) and a small gating network that activates only the most relevant ones. A 30B MoE model might activate only 3B parameters per request thus giving it the capacity of a large model but the compute cost of a much smaller one.
This section is intentionally short on general MoE theory (DigitalOcean’s existing articles on Expert Parallelism and MoE inference costs cover that well). The focus here is on the specific property that makes MoE useful as a classifier inside a routing layer.
Dense vs. Sparse: The Core Difference
A standard Transformer is what most people mean when they say “LLM” and is a dense model. Every forward pass activates every parameter. If the model has 70B parameters, every token you generate touches all 70B.
A Mixture-of-Experts model replaces the dense feed-forward network (FFN) layers with a set of N expert networks and a small gating network. For each token, the gating network selects only the top k experts (typically k=2) and routes the token through those. The other N - k experts do nothing for that token.
The Plano-Orchestrator-30B-A3B model that powers DigitalOcean’s Inference Router has 30B total parameters but only activates approximately 3B per forward pass. That’s what the “A3B” means in the model name: 30B total, 3B active.
Dense model (70B): [token] → all 70B parameters activated → output
MoE model (30B-A3B): [token] → gating network → top-2 experts (~3B) → output
↑
28B parameters sit idle for this token
This separation of total parameters from active parameters is the key property. A MoE model can have the capacity of a large model (because its total parameter count is high) while running at the compute cost of a much smaller one (because only a fraction activates per pass).
How the Gating Network Selects Experts
The gating network is a learned linear layer that produces a score for each expert, then selects the top-k. In mathematical terms:
For a token representation x and N experts, the gating output is:
scores = x · W_gate # project token into expert-score space
top_k_indices = TopK(scores, k) # select the k highest-scoring experts
weights = Softmax(scores[top_k_indices]) # normalize to get contribution weights
output = Σ weights[i] · Expert_i(x) # weighted sum of selected expert outputs
The model learns during training which kinds of inputs each expert should handle. Experts don’t get manually assigned topics, and they specialize through gradient descent on whatever patterns the training data rewards.
One practical problem this creates is load imbalance: if the gating network routes most tokens to the same two experts, the other experts never get trained, and the model degrades. MoE training adds an auxiliary loss term that penalizes imbalanced routing, pushing tokens to distribute more evenly across experts.
Why MoE Properties Make It Good for Routing
The routing problem, classifying a conversation’s intent and mapping it to the right model, has a specific structure:
- High capacity needed: The router must generalize across hundreds of different task types, user phrasings, and conversation patterns. A 1B dense model may not have enough representational capacity to handle this well.
- Low compute budget: The routing decision must happen in the request path. Every millisecond it takes is milliseconds added to the user’s wait time before the first token.
MoE directly addresses both. The 30B-A3B model has the capacity of a 30B model enough to handle diverse routing scenarios well but runs at approximately the compute cost of a 3B dense model. That’s why it resolves intent in ~200ms at inference time.
A 3B dense model would be fast but might not generalize well enough across complex multi-turn conversations. A 30B dense model would generalize well, but would be too slow in the request path. The MoE architecture finds the middle ground.
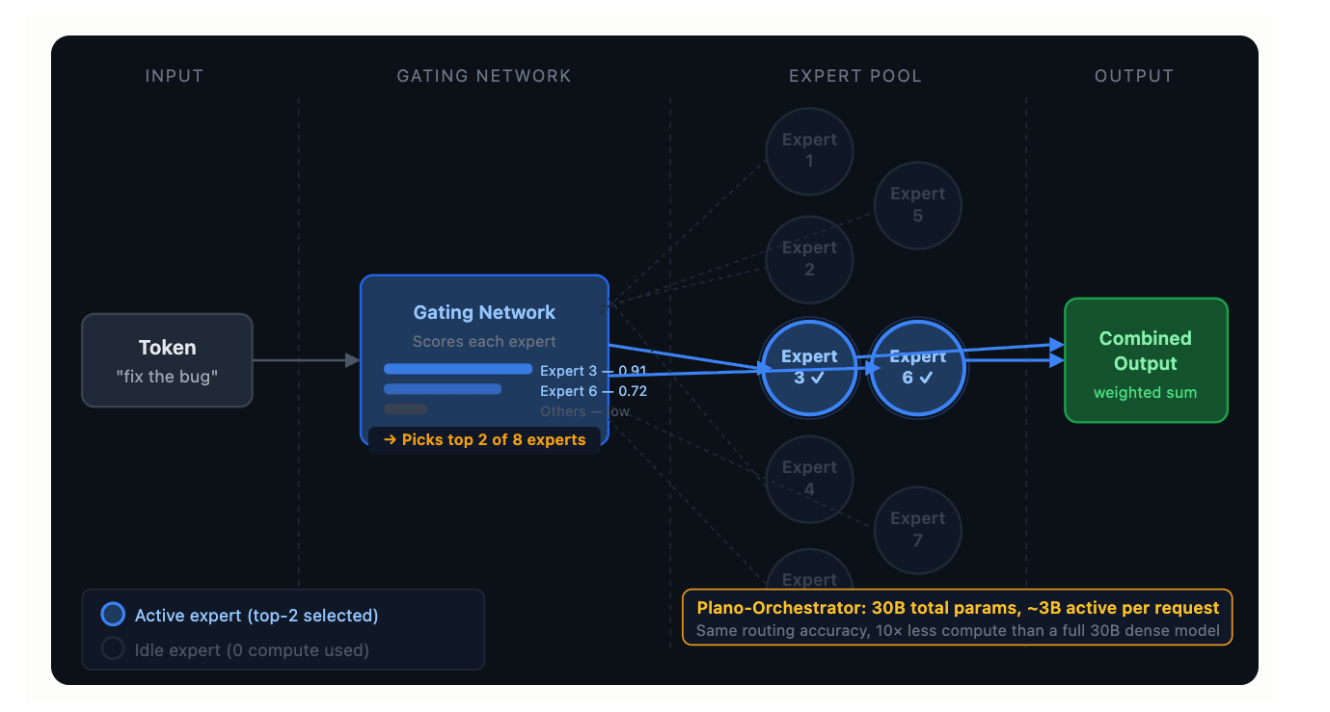
The Bridge: Token Routing → Request Routing
Inside a MoE model, a gating network routes tokens to expert sub-networks. In DigitalOcean’s Inference Router, a MoE model acts as the gating network that routes entire requests to separate model endpoints.
Inside a MoE model:
token → gating network → expert_2, expert_7 (of 64) → combined output
In DigitalOcean's Inference Router:
request → Plano-Orchestrator (a MoE model) → model_endpoint_A (of N) → response
The problem structure is the same, that is, classify an input, direct to the best handler, aggregates or passes through the result, just operating at a different granularity. The MoE architecture was chosen for the router, not because it’s fashionable, but because its specific properties (high capacity, low active compute) match what routing requires.
How DigitalOcean’s Inference Router Works
Every request sent to the router:software-engineering or any custom router goes through two phases before it reaches a model. This section walks through each one in detail.
Phase 1: Intent Resolution
When a request arrives, Plano (the open-source proxy powering the router) passes the conversation along with the natural-language descriptions of all configured tasks into the Plano-Orchestrator model. The model’s job is to emit a JSON routing decision:
{"route": "code_generation"}
or, if nothing matches:
json
{"route": "other"}
That’s it. The model doesn’t generate prose. It doesn’t explain its reasoning. It reads the conversation, matches it against the task descriptions, and outputs one of N+1 possible labels. This narrow scope is what makes a small, purpose-built model competitive with large general-purpose models on routing, and the task is structurally simple even if the input (multi-turn conversation) is complex.
How task descriptions enter the model:
The task name and description you configure are passed into the prompt directly as natural language. When you write:
{
"name": "bug-fixing",
"description": "Identify and fix errors or bugs in user-supplied code"
}
The model sees something like: “Does the following conversation match the task ‘bug-fixing: Identify and fix errors or bugs in user-supplied code’?” This means the quality of your routing depends on how you write those descriptions.
Handling long conversations:
Production conversations can easily run to thousands of tokens. The routing model has a token budget, and running a full tokenizer on every request in the hot path adds unacceptable overhead. Plano handles this in two steps:
- Keep the most recent turns to fit the token budget.
- If the last user message itself still overflows the budget, apply a middle-trim strategy on that message: preserve roughly 60% from the start and 40% from the end, separated by an ellipsis.
This outperforms head-only truncation because coding and agent conversations often have a setup phase at the start (“I’m building a FastAPI service that…”) and the concrete current ask at the end (“…now fix the KeyError on line 47”). Preserving both edges gives the routing model a stronger signal than dropping the end.
Phase 2: Model Ranking
Once the intent is resolved and a task is matched, the router has a pool of candidate models for that task. It then needs to pick one.
The ranking engine reads live data from two sources:
- DigitalOcean’s pricing API for current per-token costs
- Prometheus for live latency measurements (time-to-first-token, or TTFT)
Based on the task’s configured selection_policy, it sorts the candidate models:
| Policy | Sort Order |
|---|---|
prefer: cheapest |
Ascending input + output token cost |
prefer: fastest |
Ascending TTFT from live Prometheus data |
| Manual ranking | Your configured order, no re-sorting |
The ranked list is used in order: the top model gets the request. If it’s unavailable or rate-limited, the next model in the list is tried. If all task models fail, the request falls to the fallback models you configured.
Why live data matters:
Provider latency is not stable. Based on observations, the same model can vary by 2–3× in TTFT (Time to First Token — how long the model takes to return the very first word of its response) depending on time of day. A model that’s fastest at 2 am is often the slowest at 2 pm as provider traffic increases. Static ranking bakes in the low-traffic assumption and applies it all day. Live ranking catches these shifts on every request.
The metrics cache uses a read-optimized data structure — all routing decisions are read from it, but writes only happen on the configured refresh interval. There’s no lock contention on the hot path.
The Routing Model History: Arch-Router → Plano-Orchestrator
DigitalOcean’s routing model didn’t start at 30B. Understanding the progression explains why the current architecture is shaped the way it is.
V1: Arch-Router (1.5B)
Arch-Router is a 1.5B generative model fine-tuned specifically for single-route classification. It was trained on task-specific routing data, not general instruction-following data, and its only job is to return a JSON route label given a conversation and a set of task descriptions.
The results, published in Arch-Router: Aligning LLM Routing with Human Preferences, were the first validation that purpose-built beats general-purpose for routing:
| Model | Avg Latency | Routing Accuracy |
|---|---|---|
| Arch-Router (1.5B) | 51ms ± 12ms | 93.17% |
| Claude 3.7 Sonnet | 1,450ms ± 385ms | 92.79% |
| GPT-4o | 836ms ± 239ms | 89.74% |
| Gemini 2.0 Flash | 581ms ± 101ms | 85.63% |
| GPT-4o-mini | 737ms ± 164ms | 82.79% |
Arch-Router achieved higher accuracy than every frontier model tested at 51ms, 28× faster than Claude 3.7 Sonnet and 16× faster than GPT-4o. This validated the core design premise: a model trained specifically for routing outperforms a much larger model prompted to do routing.
The limitation of Arch-Router was generalization. It performed well on clean, single-turn queries but struggled with the messiness of real agentic traffic; ambiguous follow-ups, topic shifts mid-conversation, messages that don’t need routing at all.
V2: Plano-Orchestrator (4B dense / 30B-A3B MoE)
Plano-Orchestrator is the model that runs in DigitalOcean’s Inference Router today. It uses the same generative approach as Arch-Router — task descriptions in the prompt, JSON output — but is trained on richer multi-turn conversational data covering three scenarios Arch-Router wasn’t built for:
- Context-dependent routing: Messages like “do the same for London” that only make sense given prior turns
- Multi-turn flow handling: Follow-ups, clarifications, corrections, and off-topic messages
- Negative case detection: Recognizing when no specialized routing is needed (so requests fall through to fallback models cleanly)
It’s available in two sizes:
| Model | Architecture | Active Params | Avg Accuracy |
|---|---|---|---|
| Plano-Orchestrator-4B | Dense | 4B | 84.68% |
| Plano-Orchestrator-30B-A3B | MoE | ~3B active / 30B total | 87.84% |
Evaluated across 1,958 user messages in 605 multi-turn conversations spanning 130+ different agents:
| Model | General | Coding | Long-context | Average |
|---|---|---|---|---|
| Plano-Orchestrator-30B-A3B | 88.87% | 83.51% | 86.81% | 87.84% |
| GPT-5.1 | 89.71% | 77.54% | 81.28% | 86.93% |
| Claude Sonnet 4.5 | 88.53% | 74.39% | 85.53% | 86.11% |
| Plano-Orchestrator-4B | 87.41% | 71.23% | 84.26% | 84.68% |
| Gemini 2.5 Flash | 84.42% | 66.32% | 82.13% | 81.51% |
| Claude Haiku 4.5 | 81.99% | 72.63% | 85.53% | 81.05% |
The coding category shows the largest gap. The 30B-A3B model scores 83.51% versus GPT-5.1’s 77.54%, a 6-point difference. Coding conversations produce short, context-dependent messages (“fix it,” “try again,” “what about the edge case?”) that are almost meaningless without the conversation history. A model trained specifically on routing patterns in multi-turn conversations handles these better than a general-purpose model that’s been prompted to classify.
FP8 quantized variants of both models are available, reducing the memory footprint without meaningful accuracy loss.
Infrastructure: How Routing Stays Fast
The 200ms routing overhead comes from Plano’s three-layer design: Envoy handles the network layer (TLS, HTTP/2, connection pooling), a WASM filter running inside Envoy handles provider format translation between OpenAI, Anthropic, Gemini, and others at zero network cost, and Brightstaff a Rust binary and runs the actual intent resolution and model ranking logic using async tasks rather than threads, with no garbage collection pauses that could stutter token delivery.
For a detailed walkthrough of why each layer is built the way it is, DigitalOcean’s engineering blog post How We Built DigitalOcean Inference Router covers the implementation in full, including the WASM sandbox constraints, the hermesllm provider abstraction crate, and the Brightstaff concurrency model.
Setting Up DigitalOcean Inference Router
For a full walkthrough of credentials, preset routers, custom router creation via API, and Python SDK usage, refer to:
- Inference Routing: Matching Models to Tasks, Not Just Requests — hands-on tutorial covering authentication, preset routers, and custom router setup with working code.
- How to Use Inference Router — DigitalOcean Docs — official reference for the router configuration options, and the Control Panel workflow.
The short version: set MODEL_ACCESS_KEY, point any OpenAI-compatible client at https://inference.do-ai.run/v1, and change "model" to "router:your-router-name".
Session Pinning for Agentic Loops
This is the least obvious feature, and also one of the most important for agentic workloads.
When an AI agent runs a multi-turn task, which can include plan, execute, check output, and iterate, successive prompts look different enough that the router may select different models across turns. This creates two compounding problems:
Problem 1: Behavioral inconsistency. Different models have different output formats, tool-calling conventions, and writing styles. Switching models mid-session means the agent’s parser may fail on a response that uses a slightly different JSON structure than the previous turn.
Problem 2: KV cache invalidation. Model providers use prefix-based KV caching: if the same token sequence hits the same model, the attention state for those tokens is reused from cache. Cached input tokens are billed at 50–90% lower rates than fresh tokens (exact discount depends on provider). In a 15-turn agentic loop where the system prompt and earlier turns make up 90% of the input, model-switching means 0% cache hits — full price every turn.
DigitalOcean’s Inference Router solves this with the X-Model-Affinity header. Send a session identifier with the first request; the router makes a normal routing decision and caches which model it selected. All subsequent requests with the same affinity ID skip routing and go directly to the cached model.
import os
import httpx
MODEL_ACCESS_KEY = os.environ["MODEL_ACCESS_KEY"]
SESSION_ID = "agent-session-42" # any unique identifier per agent session
headers = {
"Authorization": f"Bearer {MODEL_ACCESS_KEY}",
"Content-Type": "application/json",
"X-Model-Affinity": SESSION_ID # <-- pin this session
}
# Turn 1: Normal routing decision, result cached for SESSION_ID
response_1 = httpx.post(
"https://inference.do-ai.run/v1/chat/completions",
headers=headers,
json={
"model": "router:software-engineering",
"messages": [
{"role": "user", "content": "Write a FastAPI endpoint that accepts a user ID and returns their profile"}
]
}
)
result_1 = response_1.json()
print(f"Turn 1 - Model selected: {result_1['model']}")
# Turn 2: Routing skipped, same model reused. KV cache from Turn 1 is valid.
response_2 = httpx.post(
"https://inference.do-ai.run/v1/chat/completions",
headers=headers,
json={
"model": "router:software-engineering",
"messages": [
{"role": "user", "content": "Write a FastAPI endpoint that accepts a user ID and returns their profile"},
{"role": "assistant", "content": result_1["choices"][0]["message"]["content"]},
{"role": "user", "content": "Now add input validation and return a 404 if the user doesn't exist"}
]
}
)
result_2 = response_2.json()
print(f"Turn 2 - Model selected: {result_2['model']}") # Same as Turn 1
For a 15-turn loop with a 4,000-token system prompt and 90% cache hit rate, the cost savings on input tokens alone are in the range of 45–80% per turn compared to no caching.
Benchmarks — What Routing Actually Saves
This section uses concrete numbers from DigitalOcean’s published benchmarks and a worked cost example to show where routing saves money, where it doesn’t, and what the latency tradeoff looks like.
Routing Accuracy: What 87.84% Means in Practice
The Plano-Orchestrator-30B-A3B model achieves 87.84% average routing accuracy across 1,958 messages in 605 multi-turn conversations.
What happens when routing is wrong? Three outcomes are possible:
- The fallback handles it correctly. If the router routes to “fallback,” the fallback model (typically a capable general-purpose model) answers the request adequately. No quality loss.
- A neighboring task handles it adequately. A code-review request routed to code-generation still gets a useful response — the model isn’t blind to the actual content, just the routing label.
- Quality degrades. A complex architecture question routed to a cheap summarization model produces a worse answer.
Outcome 3 is the concern. In practice, DigitalOcean’s preset routers are designed so that adjacent tasks share overlapping model pools, and the quality difference between “routed correctly” and “routed to a neighboring task” is small. But this is why testing your router against real traffic before production matters.
The comparison point isn’t “87.84% vs 100%.” It’s “87.84% from a 200ms model vs 0% from a static config that always routes everything to one expensive model.” Static routing has 100% determinism but 0% intelligence.
Routing Overhead: When 200ms Matters and When It Doesn’t
Every routing decision adds approximately 200ms before the first token. This is not zero, and it’s worth being clear about when it matters.
When 200ms is negligible: In interactive chat applications, users wait for the first token anyway. A frontier model like GPT-5.2 may have a TTFT of 800ms–2s under load. Adding 200ms routing overhead on top of a 1.2s TTFT results in a 1.4s perceived latency, a 17% increase, not noticeable during normal conversations.
When 200ms is significant: Real-time applications where TTFT is the dominant user experience metric. If you’re building a voice assistant where the first token in under 300ms is a hard requirement, and the routing overhead alone is 200ms, that’s 67% of your budget on routing. In this case, either use the 4B dense model variant (lower overhead) or a preset router that doesn’t require intent classification (e.g., a single-task router with speed optimization policy).
When 200ms saves more than it costs: When routing sends a request to a faster model than you would have used otherwise. If your static config defaults to GPT-5.2 (TTFT: ~1,100ms), and the router classifies the request as simple and sends it to a faster model (TTFT: ~350ms), the net latency is 350ms + 200ms = 550ms — still 50% faster than the static config.
Static routing: [request] ──────────────────── GPT-5.2 ── TTFT: 1,100ms
Router: [request] ── 200ms routing ─── Cheaper/faster model ── TTFT: 350ms
Net TTFT with routing: 550ms (50% faster than static)
Cost: A Worked Example
Suppose you’re running a coding agent that generates 10 million output tokens per day. Based on the typical task distribution in a coding agent:
| Task Type | Estimated Share | Example |
|---|---|---|
| Simple lookups, syntax checks, explanations | 35% | “What does this error mean?” |
| Moderate code generation | 40% | “Write a function to validate this input” |
| Complex reasoning, architecture, and debugging | 25% | “Why is this causing a race condition?” |
With a frontier-only static config at $15/million output tokens (approximate GPT-5.2 pricing):
10M tokens/day × $15/M = $150/day → $4,500/month
With routing that sends the 35% simple tasks to a $1/M token model, 40% moderate tasks to a $5/M model, and keeps 25% complex tasks on the $15/M model:
3.5M tokens × $1/M = $3.50/day
4.0M tokens × $5/M = $20.00/day
2.5M tokens × $15/M = $37.50/day
Total: $61/day → $1,830/month
That’s a 59% reduction on the output token bill from routing alone, with no changes to which model handles complex tasks. Your actual savings will vary based on task mix and current model pricing.
DigitalOcean Inference Engine
Inference Router is one layer within DigitalOcean’s Inference Engine — the broader platform for running foundation models in production. Understanding the full stack helps determine what the router can and can’t dispatch.
The Inference Engine has three serving modes:
Serverless Inference — pay per token, no GPU reservation. Requests are served from shared GPU capacity. Best for variable or unpredictable traffic where you don’t want to pre-commit to dedicated hardware. The router can dispatch to serverless models.
Dedicated Inference — reserved GPU capacity for your workload. Predictable latency, no cold-start overhead, suitable for compliance requirements where you need isolated compute. The router can dispatch to dedicated inference endpoints when the selection policy is Speed Optimization or Manual Ranking (dedicated instances are excluded from the Cost Efficiency auto-ranking because their pricing model is hourly, not per-token).
Batch Inference — async processing for offline workloads. Not in the router’s path — batch jobs are submitted separately through the batch API.
The Model Catalog currently includes 40+ models across text, image, audio, and video from OpenAI, Anthropic, Meta, Mistral, and open-source providers. Inference Router can only dispatch to text/chat models.
Analyze dashboard metrics:
Once your router is receiving traffic, the Control Panel’s Analyze tab shows:
- Total requests routed per time window
- Total token usage (input + output) across all routed models
- Task match rate: percentage of requests matched to a configured task (vs. falling through to fallback)
- Fallback rate: percentage of requests that hit the fallback model pool
A healthy router typically shows a task match rate above 85%. If your fallback rate is above 20%, your task descriptions are likely too narrow — requests that should match a task are falling through.
Evaluating before production:
Before switching production traffic to a router, use the Playground’s comparison mode: route a set of test prompts through both the router and a single frontier model side by side. Each response shows the model selected, end-to-end latency, and cost per request. The Evals feature extends this to datasets — upload 50–100 representative prompts, run evaluation, and get LLM-as-a-Judge correctness and completeness scores for the router vs. your static baseline.
Writing Task Descriptions That Actually Work
One of the less obvious findings from running Inference Router in production is that routing accuracy is highly sensitive to how task descriptions are written. The routing model reads these descriptions directly to match each request; how you write them determines how well routing works.
Here’s why this matters technically: the Plano-Orchestrator model compares each incoming message against your task descriptions using semantic matching, not keyword matching. That means your descriptions need to be specific enough to distinguish between tasks, but broad enough to cover the real variations in how users phrase the same intent.
Align Name and Description
The task name and description should be consistent, the name is a label, and the description is the elaboration. If they contradict each other, the model has a conflicting signal.
// Good: name and description reinforce each other
{
"name": "bug_fixing",
"description": "Identify and fix errors, exceptions, or incorrect behavior in user-supplied code"
}
// Bad: name says "math" but description is vague and could match almost anything
{
"name": "math",
"description": "handle anything related to numbers or calculations"
}
Be Specific Enough to Distinguish Tasks
If two task descriptions overlap significantly, the router will have difficulty distinguishing between them. This is especially problematic when both tasks point to very different model pools.
// Problematic: these two descriptions match many of the same prompts
[
{
"name": "technical_writing",
"description": "Write technical content, documentation, or explanations"
},
{
"name": "code_documentation",
"description": "Document code, write docstrings, or create API references"
}
]
// Better: make the distinctions explicit
[
{
"name": "technical_writing",
"description": "Write tutorials, blog posts, or conceptual explanations for technical audiences, not involving direct code documentation"
},
{
"name": "code_documentation",
"description": "Write inline docstrings, function comments, README files, or API reference documentation directly tied to code"
}
]
Use Noun-Centric Descriptions
Descriptions that center on the type of task (nouns) rather than the feeling of the task (adjectives) produce more stable routing. The routing model was trained on task-type patterns, not sentiment-style signals.
// Less stable: "creative" and "engaging" are vague modifiers
{
"description": "Write creative, engaging content that users will enjoy"
}
// More stable: describes the actual task structure
{
"description": "Write blog posts, social media copy, marketing emails, or promotional content"
}
Test with Real Traffic Before Tuning
The fastest way to find gaps in your task descriptions is to look at the router’s fallback rate. If it’s above 15–20%, pull a sample of the requests that fell through to fallback and ask: should these have matched one of my tasks? If yes, the description missed them — add the relevant phrasing. If no, the fallback handling is working correctly.
# Use the response header to track routing decisions in your own logs
import httpx
response = httpx.post(
"https://inference.do-ai.run/v1/chat/completions",
headers={
"Authorization": f"Bearer {os.environ['MODEL_ACCESS_KEY']}",
"Content-Type": "application/json"
},
json={
"model": "router:my-coding-router",
"messages": [{"role": "user", "content": user_message}]
}
)
route_selected = response.headers.get("x-model-router-selected-route")
model_used = response.json()["model"]
# Log these for analysis
print(f"Route: {route_selected}, Model: {model_used}")
Build a spreadsheet of (prompt, route_selected, model_used) from a day of traffic. Look at the “fallback” rows — those are your description gaps.
Production Considerations
Fallback Behavior
Every router has fallback models. These handle two distinct cases:
- No task matched: The routing model classified the request as
other— no configured task was a good fit. - Selected model is unavailable: The top-ranked model is down, returning errors, or rate-limited.
In case 2, the router cycles through remaining task-pool models in ranked order, then falls through to fallback models. Fallback models are tried in the order you specified. If all fail, the request returns an error.
The practical implication: your fallback model should be a model you’re comfortable serving any request to, since it’s your catch-all. A general-purpose model like openai-gpt-oss-120b is a common choice because it handles diverse inputs adequately and has a lower per-token cost than frontier models.
Model Aliases and Naming
The pricing API and your routing config may use different names for the same model. For example, the pricing catalog might list openai-gpt-5.2 while your YAML uses openai/gpt-5.2. Plano’s model_aliases map bridges this:
# In Plano config for self-hosted deployments
model_aliases:
"openai/gpt-5.2": "openai-gpt-5.2"
"anthropic/claude-sonnet-4": "anthropic-claude-sonnet-4.5"
On DigitalOcean’s managed router, this is handled automatically — use the model slugs from the Model Catalog.
Frequently Asked Questions
- What does the Inference Router actually do? It automatically picks which AI model should handle each request based on what the request is asking. Instead of always using one expensive model, it matches each request to the most appropriate and cost-effective model for that task.
- How does it know which model to use? It runs a small AI model (Plano-Orchestrator) in the request path that reads your message and matches it to a task type you’ve configured, like “code review” or “general questions.” It then picks the best available model for that task, sorted by cost or speed depending on your preference.
- Does it slow down my application? It adds approximately 200ms before the first response token. For most chat or agent workloads, this is not noticeable frontier models already take 800ms–2s to respond under load. If you have strict real-time requirements, the lighter 4B model variant has lower overhead.
- How much can it reduce my costs? It depends on your workload, but production data shows 40–60% cost reduction compared to routing everything to a single frontier model. Results will vary based on your task mix and model pricing at the time.
- What happens if the selected model is unavailable? The router automatically tries the next model in the task pool, then moves to your configured fallback models. Your application doesn’t need to handle this — it happens transparently, with no dropped requests.
- What if my request doesn’t match any task I’ve configured? It gets routed to your fallback models a list of general-purpose models that act as a catch-all. The router never returns an error just because a task didn’t match.
- How do I get started? Change the
modelfield in your existing API call from a specific model name to"router:software-engineering"(or another preset). No other code changes are required. Full setup instructions are in the DigitalOcean Inference Router docs.
Conclusion: What MoE-Based Routing Actually Solves
Routing every request to the same model is a cost problem, and the solutions teams have historically reached for — static model selection or application-layer classifiers — both have fundamental problems. One overpays for every request. The other adds an extra inference call on top of every request and introduces routing logic that someone has to maintain.
The approach DigitalOcean’s Inference Router takes is different in one important way: it puts a purpose-built MoE model in the infrastructure layer and makes it part of the request path, not the application layer. The 30B-A3B Plano-Orchestrator model activates ~3B parameters to resolve intent in ~200ms — fast enough to not meaningfully affect latency on interactive workloads, accurate enough (87.84% vs GPT-5.1’s 86.93%) to route correctly across complex multi-turn coding and long-context conversations.
The numbers from production support the premise: routing correctly across a mixed workload with a reasonable task distribution cuts inference costs by 40–60% compared to a single frontier model.
For most production agentic workloads — where the task mix is genuinely varied, the volume is high enough for cost to matter, and latency requirements have at least 200ms of headroom — the tradeoff is favorable.
Start with a preset router if your workload fits software engineering, writing, knowledge base, or general patterns. The model pools and selection policies are benchmarked by DigitalOcean’s data science team, and you’re routing in minutes with one string change.
Build a custom router when your task taxonomy is specific to your domain — legal document analysis, medical Q&A, financial modeling — where the preset categories don’t map cleanly.
References
DigitalOcean Resources
- How We Built DigitalOcean Inference Router — Adil Hafeez, Principal Engineer
- Inference Router Documentation
- Introducing DigitalOcean AI-Native Cloud — Paddy Srinivasan, CEO
- Inference Engine Product Page
- Plano (open source)
Research Papers
- Arch-Router: Aligning LLM Routing with Human Preferences
- RouteLLM: Learning to Route LLMs with Preference Data
- FrugalGPT: How to Use Large Language Models While Reducing Cost and Improving Performance
- LLMRouterBench: A Massive Benchmark and Unified Framework for LLM Routing
- Universal Model Routing for Efficient LLM Inference
- Signals: Trajectory Sampling and Triage for Agentic Interactions
- Shazeer et al., 2017 — Outrageously Large Neural Networks: The Sparsely-Gated Mixture-of-Experts Layer
- Fedus et al., 2021 — Switch Transformers: Scaling to Trillion Parameter Models
Plano-Orchestrator Models (HuggingFace)
Thanks for learning with the DigitalOcean Community. Check out our offerings for compute, storage, networking, and managed databases.
About the author
With a strong background in data science and over six years of experience, I am passionate about creating in-depth content on technologies. Currently focused on AI, machine learning, and GPU computing, working on topics ranging from deep learning frameworks to optimizing GPU-based workloads.
Still looking for an answer?
 This work is licensed under a Creative Commons Attribution-NonCommercial- ShareAlike 4.0 International License.
This work is licensed under a Creative Commons Attribution-NonCommercial- ShareAlike 4.0 International License.
Become a contributor for community
Get paid to write technical tutorials and select a tech-focused charity to receive a matching donation.

DigitalOcean Documentation
Full documentation for every DigitalOcean product.

Resources for startups and AI-native businesses
The Wave has everything you need to know about building a business, from raising funding to marketing your product.
The developer cloud
Scale up as you grow — whether you're running one virtual machine or ten thousand.

Start building today
From GPU-powered inference and Kubernetes to managed databases and storage, get everything you need to build, scale, and deploy intelligent applications.
