AI/ML Technical Content Strategist

Frontier models like Claude Opus 4.8 can drive agentic coding across languages from Python to C++ to GDScript; but at production scale, their per-token cost compounds fast. DigitalOcean’s Inference Router addresses this directly: it routes routine work to smaller open-source models and escalates to frontier models only when a task demands it. To measure the difference on a real multi-file codebase, we built a complete Godot 4 game, PK Shootout, entirely through OpenCode. In this build, OpenCode completed 596 routed tasks across 83 assistant turns. The project used roughly 4.1M tokens, and cost about $8.25 through the router. Most tasks routed to MiMo V2.5 and GLM-5.2, while only 2 of 596 tasks required fallback. The same build would have cost an estimated $123 (if the same number of tokens were generated) on a frontier model alone.
PK Shootout was developed over the course of a few hours using OpenCode. To power the models, we connected OpenCode to DigitalOcean’s Serverless Inference through its OAuth login, then created our own Inference Router to serve as the backend. With those two pieces in place, we built a complete Godot 4 penalty-shootout game (aim, power meter, keeper AI, opponent simulation, sudden death, end screen, and restart) without ever naming a model in our workflow. The router picked the model per task. But the more useful finding wasn’t the savings: it was discovering that the router doesn’t always run the models you configured. It makes its own cost-driven choices, and what actually ran surprised us.
This article walks through every step we took to create the game, from connecting OpenCode to hosting on App Platform. Follow along for a detailed breakdown of where things went well, where we had to step in, and the time and cost the development process actually incurred.
Connecting OpenCode to DigitalOcean
This was one of the simplest parts of the process. We logged into our DigitalOcean account, opened the Inference Router section, and created a router named game-designer with four distinct routes:
- design: the most heavily used route during the coding and design phases. It runs GLM-5.2 as its primary model, backed by Deepseek V4 Pro, Kimi K2.6, and MiMo V2.5 Pro.
- repo-qa: tuned for simple repository question answering. Pool: Gemma 4, MiMo V2.5, Arcee Trinity Large Thinking (Public Preview), and Qwen 3.5 397B A17B.
- chore: trivial, low-stakes edits that need no architectural reasoning: commit messages, docstrings, inline comments, README boilerplate, .gitignore entries, variable renames, formatting. Pool: Qwen3 Coder Flash, Ministral 3 14B, Gemma 4, and MiMo V2.5, defaulting to Gemma 4.
- debug: diagnoses runtime errors, stack traces, failing builds, and unexpected behavior, reasoning step by step to locate and fix bugs in existing code. Pool: GLM-5.2, Deepseek 3.2, MiniMax M2.5 (Public Preview), and Kimi K2.6.
This router handled 100% of the game’s development. Connecting it to OpenCode took one step: install OpenCode in your terminal, run /connect, choose Login with DigitalOcean (the OAuth path: this is the option that exposes your routers), and authorize. Run /models and your routers appear prefixed with router:. We selected router:game-designer and started building.
From there the loop is ordinary agentic development: describe a change in natural language, let the agent read the relevant files, propose edits, and apply them. What’s different is underneath: for each request the router decides which route and model should handle it, with no model name anywhere in our prompts. The rest of this article examines what we learned from leaning on that setup to build PK Shootout end to end.
Which DO-hosted models can actually drive a coding agent
The honest version of this question isn’t “which model did we pick?”. We never picked one. It’s “which models did the router assign to which kinds of work, and how did each hold up in that role?” That reframing matters, because it’s the whole premise of a router-backed workflow: you describe the task, and routing decides the model.
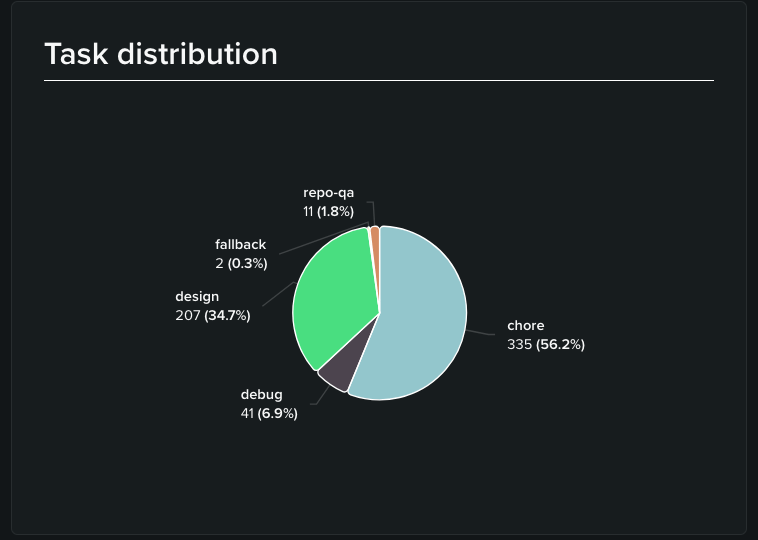
Across the build period, the router resolved 596 tasks into five buckets: chore at 335 tasks (56.2%), design at 207 (34.7%), debug at 41 (6.9%), repo-qa at 11 (1.8%), and 2 fallbacks (0.3%). The shape is what you’d expect from real development: a long tail of small edits, a solid core of design work, a thinner band of genuine debugging, and almost no pure repo Q&A.
Map that onto the model distribution and the story gets more interesting than the config alone would suggest. Three models carried essentially all the traffic: MiMo V2.5 at roughly 56%, GLM-5.2 at roughly 42%, and Gemma 4 at a thin ~2%. The many other models we listed in each route’s pool, like Deepseek, Kimi, Qwen, Ministral, etc., never had to come off the bench. In practice, two workhorses did the job.
GLM-5.2 behaved exactly as we’d configured it. Its ~42% share lines up almost perfectly with the two routes where it’s the primary model: design (34.7%) plus debug (6.9%) comes to ~41.6%. That’s a clean signal that the design and debug routing did what we designed it to do, and that GLM-5.2 was a capable enough agent to be trusted with both the architectural work and the step-by-step bug hunts: the two places where weak instruction-following would have shown up fastest.
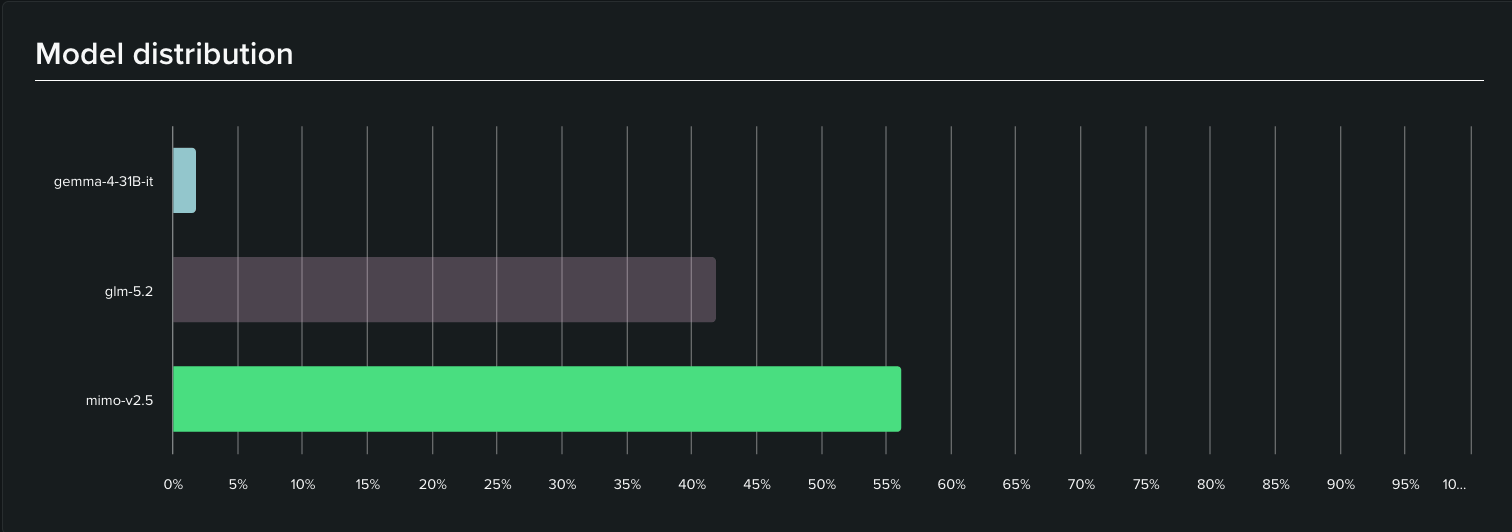
The chore route is where configuration and reality diverged, and it’s worth being upfront about. Chore was our largest bucket at 56% of all tasks, and Gemma 4 only served ~2% of calls, while MiMo V2.5, which isn’t the stated default for any route, absorbed ~56%. This is because MiMo V2.5 was effectively cheaper, leading the router to select it over Gemma 4. In other words, the router’s effective choice for low-stakes edits was MiMo V2.5, not the Gemma 4 we’d nominally set. For a founder evaluating this approach, that’s the useful caveat: routes express intent, but the model that actually answers is the router’s call, and it’s worth watching your distribution to confirm what’s really running.
What none of these models had trouble with was the agentic protocol itself. Throughout the session, the backing models reliably chained tool calls: reading files, grepping for stale references, applying targeted str_replace-style edits, and not just dumping prose and hoping. They performed multi-file consistency checks (verifying that a scene file, its script, and the calling code all agreed after a change) and reasoned correctly about non-obvious control flow, including the ordering of an await inside an async match-end function and whether a state was set before the function suspended. That’s the real bar for “can this model drive a coding agent,” and it’s a higher bar than benchmark scores: it’s not whether the model knows GDScript, but whether it can operate the tools, hold the repo in its head, and not break things it isn’t looking at. On that bar, the router’s two workhorses cleared it.
What it cost and how long it took
A working game is the headline, but the numbers underneath it are what make the workflow legible.
The build took 83 assistant turns against 17 user turns to reach a complete, documented game: a roughly five-to-one ratio of agent work to human input. Seventeen prompts carried the project from an empty Godot project to aim, power meter, keeper AI, opponent simulation, sudden death, an end screen, a restart flow, and a full README.
Summed across all 83 turns, the agent spent roughly 74.5 minutes of cumulative generation time - the model actually working, not counting the time we spent reading, testing in Godot, or deciding what to ask next. Individual turns ranged widely, from a 2.1-second one-line fix to a 529.6-second pass that wrote the entire README. That spread reflects how routed work actually distributes: a long tail of quick edits punctuated by a handful of heavy, multi-file generations. In wall-clock terms, PK Shootout came together in a few hours, about an hour and a quarter of which was the model generating.
The router adds one cost that a single hardcoded model doesn’t: the time it takes to decide where each request should go. That overhead is small and measurable. Router resolution latency held around 0.27–0.30 seconds across the period, with game-designer measured at 0.276s on June 25. At roughly a quarter-second per request, it’s the literal price of not naming a model yourself. The latency curve stays flat across the two-day window and only ticks up at the very end, so routing didn’t degrade as the project grew.
Because the bulk of traffic resolved to lower-cost models, MiMo and GLM rather than a frontier API, the total spend came in well under what the same 596 tasks would have cost on an all-frontier setup. To put this into real numbers, it took approximately 4.1M tokens to do everything - building the app, designing the plan, writing the README file, and answering a few questions about what was done. For everything, the calls to MiMo v2.5 totalled around 0.65 USD, the GLM-5.2 calls added up to about 7.56 USD, and the calls to Gemma 4 cost roughly 0.04 USD, adding up to a total of around 8.25 USD. This is compared to a total cumulative estimated cost of 18.04 USD if we were running GLM-5.2 alone without the router, or even higher costs with frontier models like ChatGPT 5.5 costing 123.00 USD on the same number of tokens. While these models could likely do the task more efficiently and in less tokens than the router methodology, it wouldn’t be enough to offset the massive per-token cost increase when using these larger models. Routing the expensive work to expensive models and leaving everything else on cheaper ones is the entire economic argument for this workflow, and the task distribution is what delivers it.
Where we had to step in
A walk-through that only shows the parts that worked isn’t worth much. The router carried the bulk of PK Shootout on its own, but three moments needed a human in the loop, and they’re the most instructive part of the build. Two were the agent doing its job well; one was a limitation worth understanding before you trust this workflow with anything load-bearing.
The first was a real bug, and the agent handled it cleanly. After an early build, the game looked right but didn’t respond: pressing the left mouse button produced no power bar and no shot. We described the symptom in plain language and asked the agent to find the cause. It read the input handler, traced the event flow, and worked out that input was never reaching _unhandled_input at all. The culprit was the full-screen Background node, a ColorRect that, like every Control in Godot 4, defaults to MOUSE_FILTER_STOP and silently consumes mouse events before they propagate. The fix was a one-line change to set the background’s mouse filter to ignore. What’s notable is that we never pointed at the cause; we only reported the symptom. The agent diagnosed the root cause itself, which is exactly the kind of step-by-step reasoning the debug route is meant to provide.
The second moment was friction, but the instructive kind: it was our fault, not the model’s. We asked to move the goal “to about 1/3 of the way down the screen.” The agent read that as one-third from the top and moved the goal upward, the opposite of what we pictured. We told it as much, then clarified with “1/3 from the bottom of the screen,” and it landed the goal where we wanted on the next try. The lesson isn’t that the model failed; it’s that natural-language spatial instructions are ambiguous, and the cost of that ambiguity is a couple of extra turns. A precise instruction the first time would have saved both. This is the ordinary texture of agentic development: the human’s job shifts from writing code to writing unambiguous intent, and you get better at it as you go.
The third moment is the one to take seriously, because it exposes the real boundary of a sub-frontier backend. When we asked the agent to write a command for generating image assets through DigitalOcean’s Serverless Inference, it didn’t know the actual API. In its reasoning it floated several plausible-looking endpoint URLs, none of them correct, before doing the right thing: it flagged its own uncertainty, asked us for the real endpoint and token rather than committing to a guess, and produced a generic OpenAI-compatible script with the specifics left as placeholders. The hedge is genuinely to its credit. But the underlying fact is the important one. The model did not reliably know current, external API details, and if we’d taken its first guess at face value we’d have shipped a broken command. We supplied the real configuration, which is documented in the final section of this article.
Taken together, these three moments draw a clean line. The agent is strong at reasoning over code it can see: diagnosing the mouse bug from symptom alone, applying targeted fixes, and recovering gracefully from an ambiguous instruction. It is weak exactly where any model is weak without retrieval: authoritative knowledge of current, external systems it can’t inspect. Knowing which side of that line a task falls on is most of what it takes to use this workflow well.
When this workflow makes sense (and when to reach for a frontier API)
By the end of the build we had enough evidence to form a defensible opinion about where a router-backed, DO-hosted setup belongs and where it doesn’t.
Reach for it when the work is mostly routine. Our task split was telling: roughly 56% chore and 35% design, with only a thin band of genuine debugging and almost no pure repository Q&A. That is what ordinary development actually looks like, a long tail of small, well-scoped edits over a steady core of design work, and it’s precisely the shape a router is built to exploit. Cheap tasks resolve to cheap models, the expensive ones escalate only when the route calls for it, and you never pay frontier prices for a docstring or a variable rename. The cost numbers bear this out directly: about 8.25 USD for the whole build against an estimated 18.04 USD on GLM-5.2 alone and far more on a frontier model. When the bulk of your work is implementation rather than novel reasoning, the router’s mix is the whole point.
Reach for a frontier API when the task depends on accurate, current knowledge of external systems, or on long-horizon architectural reasoning that has to hold together across many steps. The clearest signal we hit was the moment the backend invented a DigitalOcean endpoint it didn’t actually know. A sub-frontier model operating without retrieval will confidently fill gaps in its knowledge of current APIs and SDKs, and that’s exactly the failure mode that costs you when you least expect it. The boundary is simple to state: routine implementation, yes; authoritative external facts, verify or escalate. If a task hinges on a detail the model can’t inspect in your repo, either give it the facts yourself or route it to a model you trust to have them.
Underneath both cases is the same tradeoff, and it’s a favorable one. You give up a little speed (the router added roughly a quarter-second of resolution latency per request) and you accept the occasional fallback (2 across 596 tasks, when a route’s primary didn’t return usable output and the next model in the pool stepped in). In exchange, you never hardcode a model, never overpay for trivial work, and get a built-in safety net when a single response goes bad. For the kind of workload PK Shootout represents, that’s a trade worth making.
When a router-backed backend is the right call
PK Shootout went from an empty Godot project to a complete, playable penalty-shootout game (aim, power meter, keeper AI, opponent simulation, sudden death, an end screen, and restart) in a few hours, built entirely through OpenCode on DigitalOcean’s Serverless Inference, with an Inference Router choosing the model for every one of 596 tasks and a model name never once appearing in our prompts.
The result is a clear picture of what this workflow is good for. The agent reasoned capably over code it could see: it diagnosed a mouse-input bug from the symptom alone, applied targeted fixes across multiple files, and recovered gracefully from ambiguous instructions. The router kept cheap work on cheap models and reserved the capable ones for design and debugging, delivering the full build for around 8.25 USD. Its limits were equally clear, and they fall where any model’s do without retrieval: authoritative knowledge of current, external systems it can’t inspect. Knowing which side of that line a task sits on is most of what it takes to use the setup well.
For routine, well-scoped development (which is most development) a router-backed, DO-hosted backend is a genuinely practical way to build, and a markedly cheaper one than reaching for a frontier API by default.
Config and links
Everything in this build is reproducible with a DigitalOcean account, OpenCode, and a few minutes of setup. Here’s the exact configuration for how to use OpenCode with DigitalOcean:
- Create a model access key. In the DigitalOcean Control Panel, open Inference → Serverless Inference, then on the Get Started tab click Create a Model Access Key. A single key covers every model and every modality (text, image, audio), and the same key works for both foundation models and routers. Save it somewhere safe — you’ll need it for any non-OAuth access.
- Build the router (optional but recommended). In the Control Panel, open the Inference Router section and create a router. We named ours game-designer and gave it four routes — design, repo-qa, chore, and debug — each with a primary model and a fallback pool, as described earlier in this article. The router is what lets you describe a task and never name a model; you can skip this and call foundation models directly, but then routing is on you.
- Connect OpenCode. Install OpenCode, launch it (TUI, desktop, or web), and run:
/connect
Search for DigitalOcean and choose Login with DigitalOcean. This is the OAuth path, and it’s the one that matters: it requests the genai:read and inference:query scopes and pulls in both your foundation models and your routers. The alternative, Paste Model Access Key, authenticates fine but will not surface your routers — so if you’ve built one, use OAuth. After authorizing in the browser, run:
/models
Your routers appear prefixed with router:. We selected router:game-designer and started building. That’s the entire setup. Calling the endpoint directly. If you’d rather drive Serverless Inference from your own code instead of through OpenCode, it’s OpenAI-compatible. Point any OpenAI client at the fixed base URL and pass your model access key as a bearer token:
from openai import OpenAI
import os
client = OpenAI(
base_url="https://inference.do-ai.run/v1/",
api_key=os.getenv("MODEL_ACCESS_KEY"),
)
resp = client.chat.completions.create(
model="game-designer", # a router name, or a foundation model id
messages=[{"role": "user", "content": "Summarize this repo's architecture."}],
)
print(resp.choices[0].message.content)
The same base URL, key, and request shape work from cURL, the Gradient Python SDK, LangChain, or LlamaIndex — swap the backend and your existing code runs unchanged.
Links
Thanks for learning with the DigitalOcean Community. Check out our offerings for compute, storage, networking, and managed databases.
About the author
Still looking for an answer?
This textbox defaults to using Markdown to format your answer.
You can type !ref in this text area to quickly search our full set of tutorials, documentation & marketplace offerings and insert the link!
 This work is licensed under a Creative Commons Attribution-NonCommercial- ShareAlike 4.0 International License.
This work is licensed under a Creative Commons Attribution-NonCommercial- ShareAlike 4.0 International License.
Become a contributor for community
Get paid to write technical tutorials and select a tech-focused charity to receive a matching donation.

DigitalOcean Documentation
Full documentation for every DigitalOcean product.

Resources for startups and AI-native businesses
The Wave has everything you need to know about building a business, from raising funding to marketing your product.
The developer cloud
Scale up as you grow — whether you're running one virtual machine or ten thousand.

Start building today
From GPU-powered inference and Kubernetes to managed databases and storage, get everything you need to build, scale, and deploy intelligent applications.
