AI/ML Technical Content Strategist

LTX-2 has proven already to be one of the most exciting projects in Computer Vision. With their promise, which so far has been kept, to release iterative updates of their existing model suite, they have ushered in a revolution for low-cost video generation. This has been shown demonstrably by the awesome new model, LTX-2.3.
In this follow-up to our introduction to LTX-2, we are going to show how you can use LTX-2.3 to create even more complicated, expressive, and versatile videos than ever before with open-source technologies. We will start with a brief overview of what’s new in LTX-2.3, before jumping into a step-by-step demo on running LTX-2.3 using the ComfyUI and a DigitalOcean GPU Droplet.
Key Takeaways
- Significant Iterative Improvements: LTX-2.3 marks a major leap over its predecessor, specifically addressing previous weaknesses in image-to-video generation (reducing “freezing” and the Ken Burns effect) and enhancing prompt adherence through a text connector that is four times larger.
- Production-Ready Fidelity: The model introduces native portrait video support (up to 1080×1920) and a rebuilt latent space. This results in sharper fine details—such as hair and text—and cleaner, artifact-free audio alignment for more professional outputs.
- Accessible High-End Workflows: By pairing open-source tools like ComfyUI with scalable cloud infrastructure like DigitalOcean GPU Droplets (specifically H100/H200 GPUs), individual creators can now execute complex, production-grade video generation that was previously reserved for high-budget research teams.
New Features and Improvements in LTX-2.3
LTX-2.3 is the iterative step forward from LTX-2 from Ligthtricks. LTX-2.3 was released with a plethora of improvements: namely in prompt adherence and audio. In this section, we will outline each of the reported improvements in LTX-2.3, and discuss what they mean for generating your own videos.
- Sharper Fine Detail: The architects rebuilt the latent space with an updated Variational Autoencoder trained on higher-quality data. This means that fine textures like hair, text, and edge detail are better preserved through the full generation pipeline. We found in our tests that these improvements are present and noticeable.
- Tighter Prompt Adherence: LTX-2.3 allegedly uses a “4x larger text connector” to enable understanding of more complex prompts. This includes prompting multiple subjects, navigating spatial relationships, stylistic instructions, and more now resolving accurately. In our experimentation, we found that LTX-2.3 does indeed have better prompt adherence, and can handle much longer and more complex prompts with better strength.
- Stronger Image-to-Video: One problem with the original release was its relative weakness at image-to-video generation. LTX-2.3 reportedly features less freezing, less Ken Burns, and more realistic motion. With better visual consistency from the input frame, there are fewer generations we need to throw away. Paired with the improvements to prompt adherence and detail, this makes the model now quite strong for image-to-video modeling.
- Cleaner Audio: They filtered their training data and added a new vocoder. Together, this leads to fewer artifacts, fewer unexpected drops, and tighter alignment across text-to-video and audio-conditioned workflows. In practice, this makes the audio pair much more cleanly with the video outputs
Running LTX-2.3 with a GPU Droplet
To get started with LTX-2.3, the first thing we need is sufficient GPU computing power to run the models. We recommend sourcing this power from the Cloud, somewhere like DigitalOcean. With DigitalOcean’s GPU Droplets, we can get our GPU power anywhere with internet connection & access to some of the most powerful and versatile machines available for AI. Create an account and login to get access to your machine as needed.
Once you have logged in, navigate to the “Manage” drop-down menu in the left-hand sidebar of the DigitalOcean dashboard, and select GPU Droplets. Once on the GPU Droplet page, search for and click the button that says “Create GPU Droplet”. From there, choose the Data Center region that is best for your location, and then select a type of GPU. We recommend an H100 or H200 at least for this task. Add an SSH key (this is critical), and create the machine.
SSH into your GPU Droplet from your local machine. From there, navigate to the working directory of your choice. With that, we are ready to begin setting up the ComfyUI.
Setting up the ComfyUI for LTX-2.3
To get started with LTX-2.3, we first need the requisite model files. We are going to use the base template provided by the Comfy Org for this, so the following series of downloads will correctly fill the model directories we are using with the required files. Paste the following into your remote machine terminal:
git clone https://github.com/Comfy-Org/ComfyUI
cd ComfyUI
python3 -m venv venv
source venv/bin/activate
pip install -r requirements.txt
cd models/checkpoints
wget https://huggingface.co/Lightricks/LTX-2.3-fp8/resolve/main/ltx-2.3-22b-dev-fp8.safetensors
cd ../text_encoders/
wget https://huggingface.co/Comfy-Org/ltx-2/resolve/main/split_files/text_encoders/gemma_3_12B_it_fp4_mixed.safetensors
cd ../loras/
wget https://huggingface.co/Lightricks/LTX-2.3/resolve/main/ltx-2.3-22b-distilled-lora-384.safetensors
wget https://huggingface.co/Comfy-Org/ltx-2/resolve/main/split_files/loras/gemma-3-12b-it-abliterated_lora_rank64_bf16.safetensors
cd ../latent_upscale_models/
wget https://huggingface.co/Lightricks/LTX-2.3/resolve/main/ltx-2.3-spatial-upscaler-x2-1.0.safetensors
python main.py
Save the output. Then, get your machine’s Public IPv4 address, and, in a separate terminal window on your own machine, paste the following:
ssh -N -L 8188:127.0.0.1:8188 root@<your remote machine’s public IPv4 address>
Now we can take the output from the first terminal window and open the address in our local machine’s browser.
We have a template link you can access. Download the template, and upload it to the ComfyUI. If everything worked, it should look like this.
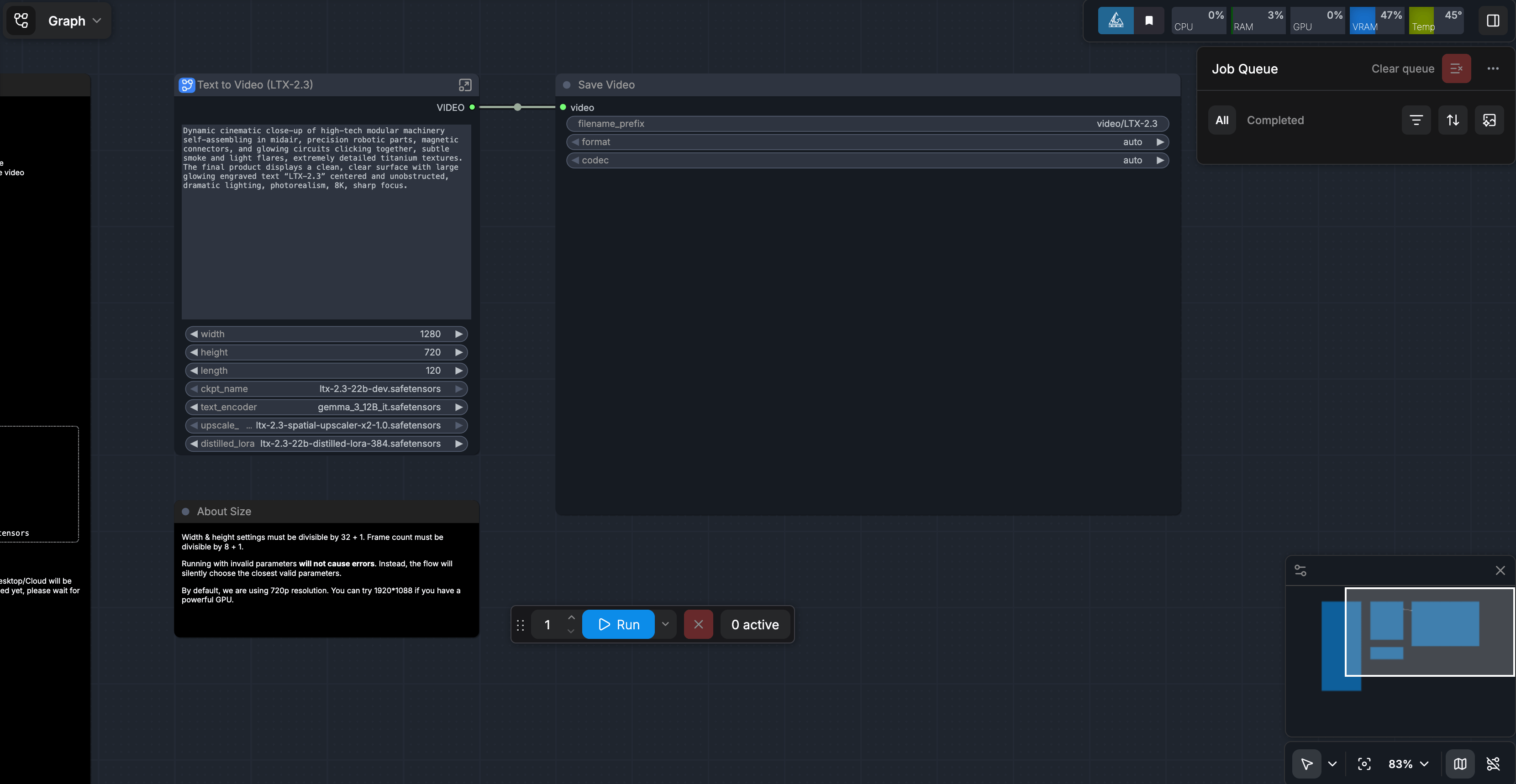
Then, when you run the prompt you should get a video like the following (but with sound):

From here, you are free to try and test the limits of LTX-2.3! We recommend testing your old LTX-2 prompts against the new model, testing the improved image-to-video capabilities, and taking full advantage of the speed and efficiency of the LTX-2.3 model using the GPU Droplet at your disposal. In our experience so far, LTX-2.3 is excellent for animating static images for media purposes, and creating wholesale videos from scratch in various styles like anime or cinematic realism.
Closing Thoughts
LTX-2.3 represents a meaningful step forward for open-source video generation, bringing higher fidelity, stronger prompt control, and more reliable audio into a workflow that is increasingly practical for real-world use. When paired with DigitalOcean GPU Droplets, what was once limited to large research teams or expensive proprietary tools is now accessible to individual developers, creators, and small teams. The combination of powerful cloud hardware and flexible tooling like ComfyUI creates an environment where experimentation is fast, scalable, and relatively affordable.
More importantly, LTX-2.3 signals where this space is heading: toward models that can reliably translate complex creative intent into polished, production-ready video. Whether you are animating still images, prototyping visual ideas, or building entirely new forms of media, the barrier to entry continues to drop. As these models improve and infrastructure becomes even more efficient, we are quickly approaching a future where high-quality video generation is as routine as image generation is today.
Thanks for learning with the DigitalOcean Community. Check out our offerings for compute, storage, networking, and managed databases.
About the author
Still looking for an answer?
 This work is licensed under a Creative Commons Attribution-NonCommercial- ShareAlike 4.0 International License.
This work is licensed under a Creative Commons Attribution-NonCommercial- ShareAlike 4.0 International License.
Become a contributor for community
Get paid to write technical tutorials and select a tech-focused charity to receive a matching donation.

DigitalOcean Documentation
Full documentation for every DigitalOcean product.

Resources for startups and AI-native businesses
The Wave has everything you need to know about building a business, from raising funding to marketing your product.
The developer cloud
Scale up as you grow — whether you're running one virtual machine or ten thousand.

Start building today
From GPU-powered inference and Kubernetes to managed databases and storage, get everything you need to build, scale, and deploy intelligent applications.
