Prompt Caching for Anthropic and OpenAI Models: Building Cost-Efficient AI Systems
By Satyam Namdeo
- Updated:
- 9 min read
Large Language Models (LLMs) have become a foundational component for modern AI applications, from developer copilots and documentation assistants to advanced troubleshooting tools. As these applications scale, one challenge quickly becomes apparent: token costs can grow rapidly when large prompts are repeatedly sent to the model.
A common architecture for production AI systems includes long system instructions, tool schemas, retrieved knowledge base documents, and conversation history. These components can easily add thousands of tokens per request. When applications handle thousands or millions of requests per day, repeatedly processing the same static prompt content becomes expensive.
To address this problem, prompt caching has emerged as an essential optimization technique supported by major model providers such as Anthropic and OpenAI.
Prompt caching allows repeated prompt segments to be reused across requests, significantly reducing both latency and cost. In this article, we will explore:
- What prompt caching is and how it works
- How Anthropic and OpenAI implement caching
- The billing implications and cost advantages
- Real-world use cases
- A realistic production architecture that can reduce token costs by 70–90%
We will also show how prompt caching can be implemented when using models via DigitalOcean.
What is Prompt Caching?
Prompt caching is a mechanism where large portions of a prompt that remain identical across requests are stored and reused, instead of being reprocessed every time.
Since information like System instructions, tool schemas, guardrails, documentations ,etc rarely changes, repeatedly sending it wastes computation and increases token usage costs. Prompt caching solves this by:
- Storing previously processed prompt segments.
- Reusing those segments when identical requests appear again.
- Charging a much lower price for cached tokens.
This optimization is especially powerful in production systems where large static prompts are combined with small dynamic queries.
How Prompt Caching Works
At a high level, prompt caching works by identifying prefix tokens that remain identical across multiple requests.
If a request begins with the same sequence of tokens as a previous request, the model provider can reuse the previously processed representation rather than recomputing it.
The workflow looks like this:
- In Initial request, full prompt is processed and static segments are stored in the cache
- Whereas in Subsequent request,
- The model detects identical prefix tokens
- Cached tokens are reused
- Only the new tokens are processed
This approach reduces compute work significantly because LLM inference is most expensive when processing large prompts.
Advantages of Prompt Caching
Prompt caching provides several important benefits for production AI systems.
1. Major Cost Reduction
Prompt caching can significantly reduce the cost of running LLM applications because tokens reused from earlier requests are billed at a much lower rate than newly processed tokens. For example, in GPT-5, standard input tokens cost about $1.25 per million tokens, while cached input tokens cost only $0.125 per million tokens, making cached tokens around 10× cheaper.
2. Reduced Latency
Since cached prompt segments do not need to be recomputed, the model can process requests faster. This improves user experience in interactive applications such as Chat Assistants, Coding Copilots and Documentation Search tools
3. Improved Scalability
Applications handling large traffic volumes benefit significantly because caching prevents redundant computation across thousands of requests.
This makes AI systems more economically viable at scale.
Common Use Cases Where Prompt Caching Helps
Prompt caching is most effective when large prompt segments remain identical across requests. Most AI apps that commonly use this include ChatGPT, Cursor, Perplexity AI, Notion AI
Retrieval-Augmented Generation (RAG)
RAG systems retrieve documents and inject them into prompts. If the retrieved documents are reused frequently, caching can significantly reduce token costs.
Typical examples include Knowledge Base Assistants, Documentation search, Internal support chatbots ,etc
AI Troubleshooting Systems
Enterprise support assistants often include system instructions, operational playbooks, and technical documentation.
These prompts can exceed several thousand tokens and are ideal for caching.
A Realistic Production Prompt Caching Architecture
A common architecture used in production AI systems organizes prompts into static and dynamic sections.
The key idea is simple: Place all large, static prompt components at the beginning of the prompt. This creates a large prefix that can be cached.
Cached Prefix
The following prompt components typically remain identical across requests:
- System prompt (large instructions)
- Tool schemas
- RAG documents
Dynamic Portion
The following components change per request:
- user query
- conversation history
- tool outputs
Production Prompt Structure
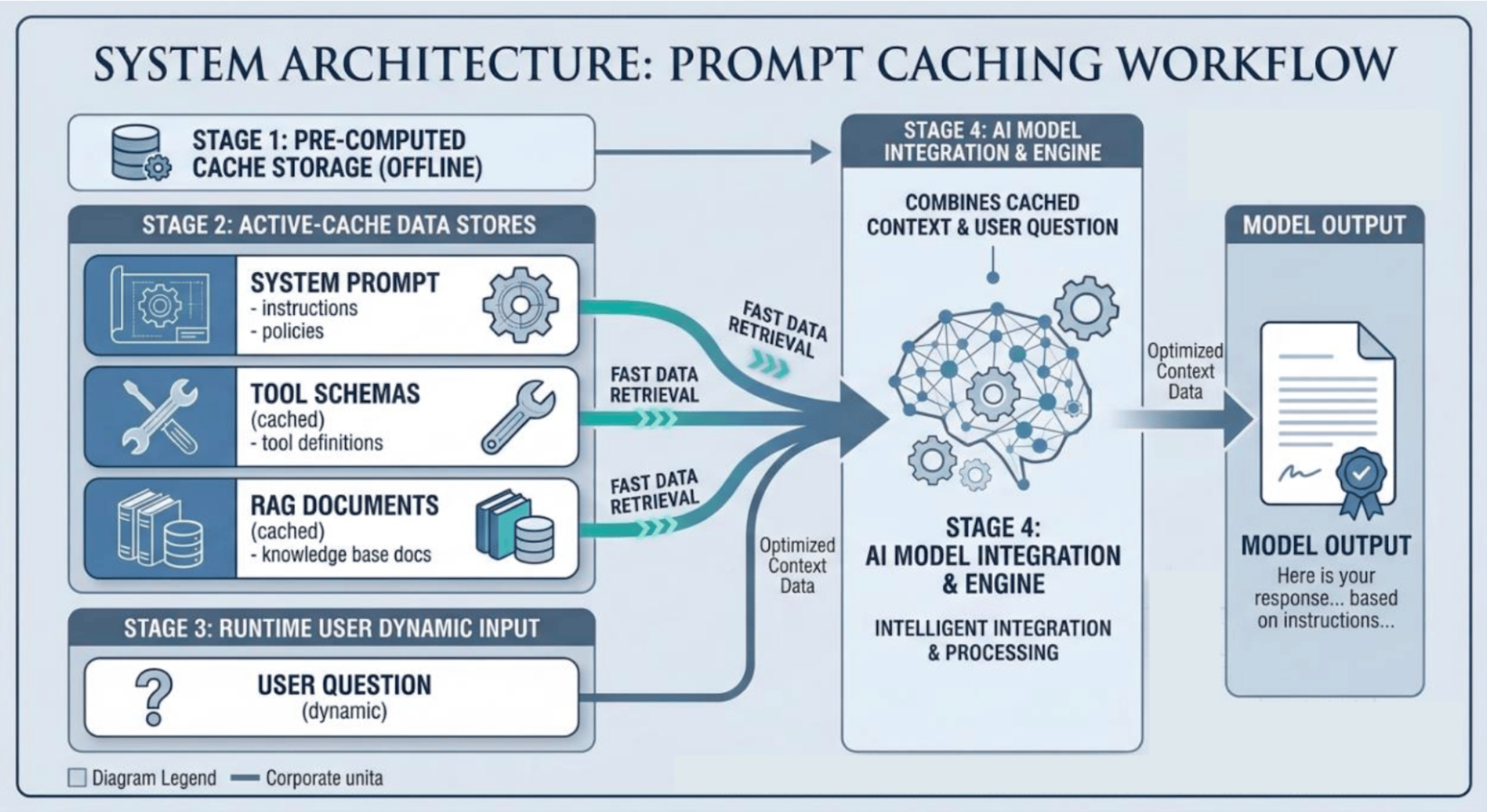
Example Production AI System
Consider a Kubernetes troubleshooting assistant. Example request structure:
{
"model": "gpt-5",
"input": [
{
"role": "system",
"content": "You are a senior Kubernetes networking engineer..."
},
{
"role": "system",
"content": "TOOLS AVAILABLE:\n1. search_k8s_docs(query)..."
},
{
"role": "system",
"content": "DOCUMENT: CoreDNS runs as a deployment in Kubernetes..."
},
{
"role": "user",
"content": "How does CoreDNS know which pod IPs belong to a service?"
}
],
"max_output_tokens": 200
}
| Component | Tokens | Cacheble |
|---|---|---|
| System instructions | 1,500 | Yes |
| Tool schema definitions | 1,000 | Yes |
| RAG documentation | 3,500 | Yes |
| Conversation history | 300 | No |
| User question | 50 | No |
Total input tokens: 6,350 (6000 cacheble) Model output tokens: 200
Cost Comparison
Scenario 1 — Without Prompt Caching
Every request processes the full prompt.
Input cost: 6,350 × $1.25 / 1,000,000 = $0.00794
Output cost: 200 × $10 / 1,000,000 = $0.002
Total cost per request: $0.00994
Scenario 2 — With Prompt Caching
Cached tokens: 6,000 Non-cached tokens: 350
With caching enabled, the first request runs at full price to populate the cache. After that, repeated tokens are billed at the cached rate.
Cached token cost: 6,000 × $0.125 / 1,000,000 = $0.00075
Non-cached input tokens: 350 × $1.25 / 1,000,000 = $0.00044
Output tokens: 200 × $10 / 1,000,000 = $0.002
Total cost per cached request: $0.00319
Savings per request
- Without caching: $0.00994
- With caching: $0.00319
Savings per request: $0.00675 (~68% reduction)
| Requests per Day | Monthly Cost (No Cache) | Monthly Cost (With Cache) | Monthly Savings |
|---|---|---|---|
| 10,000 | $2,981 | $956 | $2,025 |
| 100,000 | $29,813 | $9,563 | $20,250 |
| 1,000,000 | $298,125 | $95,625 | $202,500 |
This is why prompt caching is critical for production LLM systems.
Prompt Caching with Anthropic Models (via DigitalOcean)
Prompt caching with Anthropic models is explicitly controlled by the developer. Developers can mark sections of the prompt as cacheable using the cache_control parameter.
Example:
{
"role": "user",
"content": {
"type": "text",
"text": "This is cached for 1h.",
"cache_control": {
"type": "ephemeral",
"ttl": "1h"
}
}
}
Mixed Cached and Non-Cached Content
{
"role": "developer",
"content": [
{
"type": "text",
"text": "Cache this segment for 5m.",
"cache_control": {
"type": "ephemeral",
"ttl": "5m"
}
},
{
"type": "text",
"text": "Do not cache this segment"
}
]
}
Tool Output with Cache Control
{
"role": "tool",
"tool_call_id": "tool_call_id",
"content": [
{
"type": "text",
"text": "Tool output cached for 5m.",
"cache_control": {
"type": "ephemeral",
"ttl": "5m"
}
}
]
}
Anthropic Relay Example
Prompt caching can also be used via Anthropic Relay:
{
"max_tokens": 200,
"system": [
{
"type": "text",
"text": "You are an expert Kubernetes networking assistant.",
"cache_control": { "type": "ephemeral" }
}
],
"messages": [
{
"role": "user",
"content": [
{ "type": "text", "text": "Explain how CoreDNS works in Kubernetes." }
]
}
]
}
Cache Configuration
Important details:
- Minimum cached block size: 1024 tokens
- Default TTL: 5 minutes
- Optional TTL: 1 hour
- Up to four cache breakpoints.
Example Response
Initial request:
"usage": {
"cache_created_input_tokens": 1043,
"cache_read_input_tokens": 0
}
Subsequent request:
"usage": {
"cache_created_input_tokens": 0,
"cache_read_input_tokens": 1043
}
This indicates the tokens were reused from the cache.
Anthropic Billing Behavior
Key pricing characteristics:
- Cache writes cost 25% more than base input tokens
- Cache hits cost 10% of the base token price (90% savings)
Official pricing details here.
Prompt Caching with OpenAI Models (via DigitalOcean)
Prompt caching in OpenAI models works differently. Caching is implicit and automatic rather than explicitly controlled.
Key characteristics:
- No explicit cache control parameter required
- Cache reuse is best effort
- Cache windows are typically short (minutes)
Developers can optionally provide two fields: prompt_cache_key and prompt_cache_retention
Chat Completions Example
{
"model": "gpt-4.1",
"prompt_cache_key": "k8s-networking-docs-v1",
"prompt_cache_retention": "extended",
"messages": [
{
"role": "system",
"content": "You are a Kubernetes networking expert."
},
{
"role": "system",
"content": "DOCUMENT: CoreDNS resolves service names..."
},
{
"role": "user",
"content": "How does CoreDNS know which pod IPs belong to a service?"
}
],
"max_tokens": 200
}
Responses API Example
{
"model": "gpt-4.1",
"prompt_cache_key": "k8s-networking-docs-v1",
"prompt_cache_retention": "extended",
"input": [
{
"role": "system",
"content": "You are a Kubernetes networking expert."
},
{
"role": "system",
"content": "DOCUMENT: CoreDNS resolves service names."
},
{
"role": "user",
"content": "How does kube-proxy load balance traffic to pods?"
}
],
"max_output_tokens": 200
}
Example Usage Response
{
"usage": {
"input_tokens": 1500,
"output_tokens": 180,
"input_tokens_details": {
"cached_tokens": 1400
}
}
}
Meaning:
- 1500 total input tokens
- 1400 tokens served from cache
- 100 processed normally
Production Use of “prompt_cache_key” and “prompt_cache_retention”
These optional parameters help improve cache reuse.
prompt_cache_key
A developer-defined identifier used to group related prompts. Example uses:
- versioning documentation prompts
- separating product environments
- isolating prompts across tenants
Example: k8s-networking-docs-v1, support-assistant-v2, product-docs-release-2025
When identical prompts share the same key, cache hits become more likely.
prompt_cache_retention
Controls how aggressively the system tries to keep the cached prefix. Typical options include default short retention and extended retention for longer reuse windows.
This is particularly useful for high traffic applications, AI assistants with stable prompt prefixes.
Official pricing details here.
Cost efficient LLM deployment with DigitalOcean
DigitalOcean supports prompt caching when using models from providers like Anthropic and OpenAI. Billing follows the per-token pricing defined by the model provider.
Developers using DigitalOcean can:
- enable Anthropic cache control parameters
- take advantage of OpenAI’s implicit caching
- monitor token usage in API responses
This allows teams to implement cost-efficient AI systems while using DigitalOcean’s developer platform. Prompt caching has become one of the most powerful techniques for reducing LLM infrastructure costs.
By organizing prompts into static cached prefixes and dynamic request components, developers can reduce token costs by roughly 70–90% in many real-world applications.
At scale, these savings can amount to tens or hundreds of thousands of dollars per month. As AI applications continue to grow, architectures that incorporate prompt caching will become a core part of building efficient, scalable AI systems.
For teams building production AI applications on platforms like DigitalOcean, prompt caching is not just an optimization—it is a foundational design principle for cost-efficient LLM deployment.
About the author
Related Articles

The Inference Alpha: Maximizing Frontier Models on AMD
Balaji Varadarajan
- June 10, 2026
- 12 min read

The Inference Tax: How Prefix-Aware Routing Eliminates the Hidden Cost of LLMs at Scale
- June 1, 2026
- 13 min read

DigitalOcean Serverless Inference: A Deep Dive
- June 1, 2026
- 17 min read